Difference between revisions of "ANLY482 AY2016-17 T1 Group4: Project Overview"
Jump to navigation
Jump to search

| Line 47: | Line 47: | ||
===Nature of Dataset=== | ===Nature of Dataset=== | ||
| − | The team was able to obtain ten different datasets from the main Database, of which eight were usable and relevant to our area of analysis. The first dataset “Client”, the primary Client dataset, contains approximately 510,000 rows of client records, with 105 unique columns, which came in a “.TXT” formatted flat file. The second dataset, “Contract”, that was provided was the contract header dataset that held each clients’ contract data, containing approximately 1.4 million rows of records, with 234 unique columns, which came in a “.TXT” formatted flat file. The third dataset, “Life”, that was provided was the Life Insurance data that was linked to each contract, containing approximately 414,000 rows of records, with 27 unique columns, which came in a “.TXT” formatted flat file. The fourth dataset, “Coverage”, that was provided was the coverage data that was linked to each contract, containing approximately 2.86 million rows of records, with 102 unique columns, which came in a “.TXT” formatted flat file. The fifth dataset, “Agent”, that was provided was the agent data linked to each client, containing approximately 10800 rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file. The sixth dataset, “Payer”, that was provided was the payee data linked to each contract, containing approximately 1.14 million rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file. The seventh dataset, “ClientRel”, that was provided was a table linking agent data, client data and life insurance data together, containing approximately 2.482 million rows of records, with 11 unique columns, which came in a “.TXT” formatted flat file. The eighth dataset, “ClientExtra”, that was provided was the extra client data linked to each client, containing approximately 396,000 rows of records, with 21 unique columns, which came in a “.TXT” formatted flat file. | + | The team was able to obtain ten different datasets from the main Database, of which eight were usable and relevant to our area of analysis. |
| + | |||
| + | *The first dataset “Client”, the primary Client dataset, contains approximately 510,000 rows of client records, with 105 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The second dataset, “Contract”, that was provided was the contract header dataset that held each clients’ contract data, containing approximately 1.4 million rows of records, with 234 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The third dataset, “Life”, that was provided was the Life Insurance data that was linked to each contract, containing approximately 414,000 rows of records, with 27 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The fourth dataset, “Coverage”, that was provided was the coverage data that was linked to each contract, containing approximately 2.86 million rows of records, with 102 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The fifth dataset, “Agent”, that was provided was the agent data linked to each client, containing approximately 10800 rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The sixth dataset, “Payer”, that was provided was the payee data linked to each contract, containing approximately 1.14 million rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The seventh dataset, “ClientRel”, that was provided was a table linking agent data, client data and life insurance data together, containing approximately 2.482 million rows of records, with 11 unique columns, which came in a “.TXT” formatted flat file. | ||
| + | |||
| + | *The eighth dataset, “ClientExtra”, that was provided was the extra client data linked to each client, containing approximately 396,000 rows of records, with 21 unique columns, which came in a “.TXT” formatted flat file. | ||
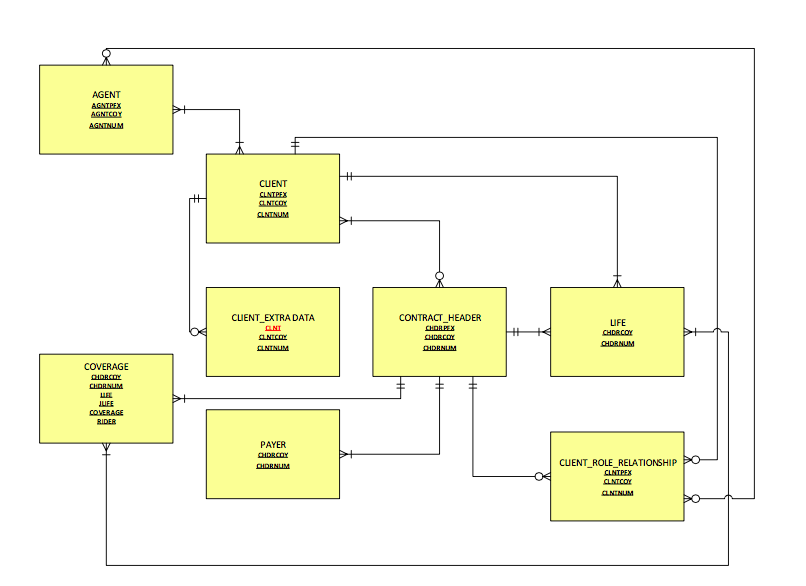
===ER Diagram=== | ===ER Diagram=== | ||
Revision as of 00:10, 17 October 2016
Background
At the insurance company, serving happiness to customers has always been the main focus. As such, we at Team Insured have been tasked to assist Tokio Marine's customer base, specifically for the Life Insurance side of the business.
The three main things that the insurance company requires our help for to do analysis on:
- Average Product Holdings per Customer
- Customer Segmentation
- Agent Segmentation.
Deeper analysis such as Need Based Analysis has also been requested. These are the three general objectives that are to be pursued for this project, so as to help the insurance company understand their customers better.
Data Source
Nature of Dataset
The team was able to obtain ten different datasets from the main Database, of which eight were usable and relevant to our area of analysis.
- The first dataset “Client”, the primary Client dataset, contains approximately 510,000 rows of client records, with 105 unique columns, which came in a “.TXT” formatted flat file.
- The second dataset, “Contract”, that was provided was the contract header dataset that held each clients’ contract data, containing approximately 1.4 million rows of records, with 234 unique columns, which came in a “.TXT” formatted flat file.
- The third dataset, “Life”, that was provided was the Life Insurance data that was linked to each contract, containing approximately 414,000 rows of records, with 27 unique columns, which came in a “.TXT” formatted flat file.
- The fourth dataset, “Coverage”, that was provided was the coverage data that was linked to each contract, containing approximately 2.86 million rows of records, with 102 unique columns, which came in a “.TXT” formatted flat file.
- The fifth dataset, “Agent”, that was provided was the agent data linked to each client, containing approximately 10800 rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file.
- The sixth dataset, “Payer”, that was provided was the payee data linked to each contract, containing approximately 1.14 million rows of records, with 51 unique columns, which came in a “.TXT” formatted flat file.
- The seventh dataset, “ClientRel”, that was provided was a table linking agent data, client data and life insurance data together, containing approximately 2.482 million rows of records, with 11 unique columns, which came in a “.TXT” formatted flat file.
- The eighth dataset, “ClientExtra”, that was provided was the extra client data linked to each client, containing approximately 396,000 rows of records, with 21 unique columns, which came in a “.TXT” formatted flat file.
ER Diagram

Methodology