Difference between revisions of "ISSS608 2017-18 T3 Assign Hasanli Orkhan Methodology"
Orkhanh.2017 (talk | contribs) |
Orkhanh.2017 (talk | contribs) |
||
| Line 87: | Line 87: | ||
For the Edge data which contains 137 rows I have created two more columns Quarter and Time of the day in case I am going to investigate on quarterly or hourly basis. | For the Edge data which contains 137 rows I have created two more columns Quarter and Time of the day in case I am going to investigate on quarterly or hourly basis. | ||
<br><br> | <br><br> | ||
| − | < | + | <h2>Using Gephi parameters to visualize network</h2> |
| − | |||
| − | |||
By combining all the suspicious four data sets provided by insider we might detect people who mostly communicate and also changing settings of Nodes Ranking by size to Degree, In-Degree and Out-Degree we can see which people mostly getting calls, emails, invitations and which people sending the most respectively. Layout for network used in this case is Frutcherman Reingold layout. By hovering on the images we can see the details. | By combining all the suspicious four data sets provided by insider we might detect people who mostly communicate and also changing settings of Nodes Ranking by size to Degree, In-Degree and Out-Degree we can see which people mostly getting calls, emails, invitations and which people sending the most respectively. Layout for network used in this case is Frutcherman Reingold layout. By hovering on the images we can see the details. | ||
<br><br> | <br><br> | ||
Revision as of 21:40, 8 July 2018

|
|
|
|
|
Contents
Data Preparation
In all the data sets provided in this mini case, we need to create a new column for timestamp. I have used SAS JMP to create a new column by starting from May 11, 2015 14:00. By taking the seconds value of 5/11/2015 and 14:00, we can add up by given seconds value with created new columns values to get the actual date and time.



Same formulas were applied for creating similar columns for other datasets. Consequently, we check for duplicates in the data, duplicates from Calls, Purchases data set were removed.
Firstly, I remove May and June months from 2015 because are incomplete, as well as, if we look at quarterly data later in our analysis we cannot get quarterly information with that two months. By keeping them, I would make some noise in my data.
Methodology for Question 1
In order to create a single picture of the company, characterize changes in the company over time and to see the patterns whether the company is growing or not I am going to use Tableau for demonstrating calls, emails, meetings and purchases pattern over time.
I have created two dashboards in Tableau, where one of them shows overall trend of calls, emails, meetings and purchases by months of 2015, 2016, 2017. Some months were filtered out to get better picture of the trend and for each line graph the range of Y axis which is the number of records was altered to see clearly the trend.

After filtering individually I put calls, emails, meetings and purchase line graphs together in the dashboard.

For both of the dashboards and plots individually reference line was drawn in order to easily detect which months are higher, lower or around the average value.

In another dashboard I demonstrated the cycle plot where we can see in which months of all the given years there is upward or downward trend.

Methodology for Question 2
Gephi Data Preparation
To prepare our data for being ready to dump into Gephi, firstly I concatenate all the 4 suspicious data sets and create new day, week, month and year columns for easy filtering in Gephi.

Next, we need to join the Suspicious_Final dataset with CompanyIndex dataset to get the labels and prepare our new created data set for Node and Edge data sets.
In order to Join data tables, first I match Source = ID and then Destination=ID, subsequently I will add two columns (First and Last) from Destination Labelled to Source Labelled data table. Before adding them, I will concatenate two columns (First and Last) into one named Label.

For running in Gephi Node data we need to keep only unique ID and Label. Thus, from Summary I take only unique ID and corresponding labels. The following is my Node dataset, where I have only 20 unique suspicious people.
c
For the Edge data which contains 137 rows I have created two more columns Quarter and Time of the day in case I am going to investigate on quarterly or hourly basis.
Using Gephi parameters to visualize network
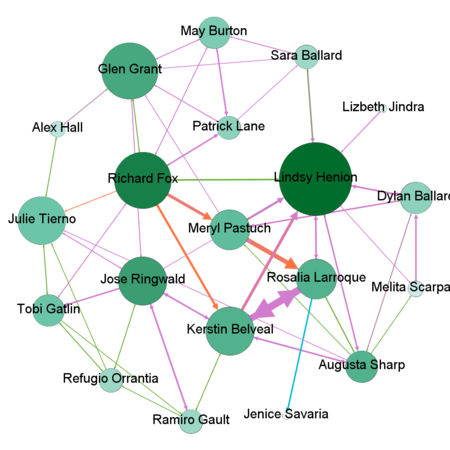
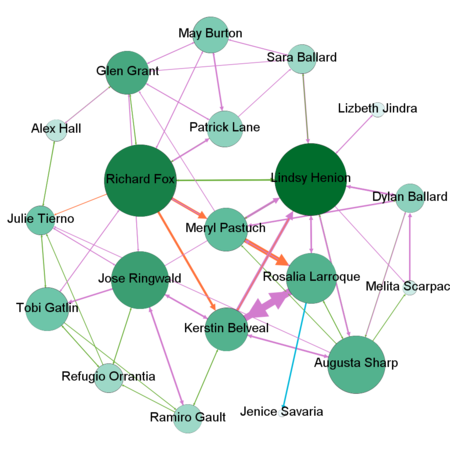
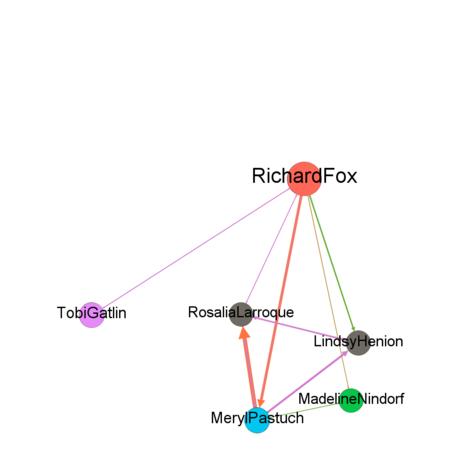
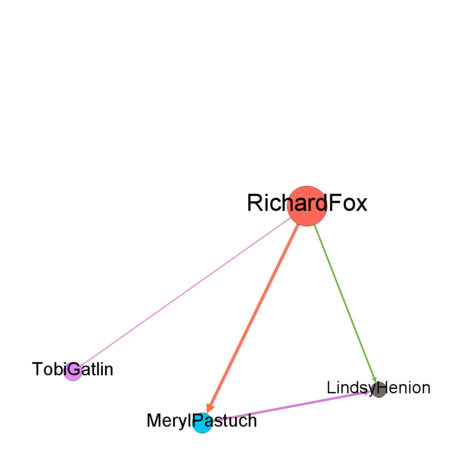
By combining all the suspicious four data sets provided by insider we might detect people who mostly communicate and also changing settings of Nodes Ranking by size to Degree, In-Degree and Out-Degree we can see which people mostly getting calls, emails, invitations and which people sending the most respectively. Layout for network used in this case is Frutcherman Reingold layout. By hovering on the images we can see the details.

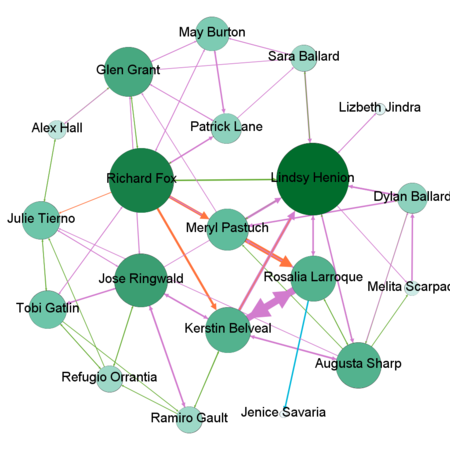
Degree
In-Degree
Out-Degree



By using Filter feature we might find out by which exact communication type individuals connected to each other. To find out which employees making suspicious purchases we will use Filter -> Attributes -> Partition -> c-type(Edge)

Merging the suspicious data set with large dataset
By applying the same methods for creating node and edge data set I have merged suspicious Source and Destination IDs with 4 larger data sets and concatenated them for further analysis of the suspicious group interrelations with other people from the large dataset.
Individuals names previously recognized as suspicious when dumping into the big dataset have been changed to “Label_Ins” which means insider provided individual. Therefore, I have 1640 Nodes and 1816 Edges in Gephi. By changing the Layout to Force Atlas 2 we are getting nicer representation for our network, however by applying Modularity measure under Statistics Tab we will disintegrate our graph into clusters such called “Mafias”.

To get better decomposition into the communities I tick Randomize. Modularity makes sense if it is greater than 0.4. In our case Modularity = 0.588 and we have 6 communities. Layout of the network graph was changed to ForceAtlas2 and scaling was adjusted to 7.

Showing only by degree might be not enough, therefore we are applying some statistics measures to identify betweenness centrality, closeness centrality and eigenvector centrality. From betweenness we can detect people who act as a bridge between other people in a network. I have changed the size and filtered out the nodes to see clearly people who has higher betweenness. Next, we will measure the Closeness Centrality which shows individuals who can influence the entire network most quickly. We filter out people with highest Centrality measure. And finally to find out the people who can have an influence not only over the people that they are connected but to the whole network we may calculate the Eigenvector Centrality.
Betweenness
Closeness
Eigenvector



From modularity above it is obvious that some people in between the clusters and by hovering on that nodes we find out some individuals that connect ‘bosses’ of that clusters. To remove people who only communicate once I will create a filter where the Degree measure is greater than one and take only people who communicated at least two times and subsequently I will remove people from each cluster that communicate only with their boss that might not be considered as suspicious individuals. After removing individuals who only communicates with only their boss in the specific community I left with 59 nodes and 228 edges, where 19 nodes was recognized by the insider as suspicious and there are the bosses of big and small communities, however, 40 people also are related to previously identified suspicious people because they play the bridge role between the bosses of several communities.
Methodology for Question 3
By assigning the betweenness value to the color of nodes which will show who is the bridge between the individuals in the network and closeness value to the size of nodes which will demonstrate which individuals may reach the whole network more quickly, I am going to construct the organizational structure of the group defined in the 2nd question.


To construct and make the organizational structure easily understandable I am using Dual Circle Layout and in parameters of the layout changing order nodes by Closeness Centrality.

To demonstrate the group composition change by the connection type, I am going to use Filter by c-type and show separately all the connections. To better demonstrate the connections between individuals I have applied Yifan Hu layout.





To show the group interactions over time I Filtered from Attributes -> Partition -> Year to catch exact years and added Month into the Year`s filter to drill down and see in which months there were higher communication intensity.


